



金沢大学医薬保健研究域医学系の細道一善准教授,大阪大学,国立遺伝学研究所および理化学研究所などの共同研究グループは,次世代シークエンス技術(※1)と機械学習(※2)を用いて,日本人集団における白血球の血液型が11パターンで構成されており,その個人差が病気や量的形質を含む50以上の表現型に関わっていることを明らかにしました。
ヒトの血液に含まれる白血球には血液型が存在し,ヒトゲノム上のHLA遺伝子(※3)の配列の個人差で決定されます。白血球の血液型は移植医療や個別化医療(※4)に際して重要ですが,HLA遺伝子構造が複雑で解読に専門技術が必要なことや高額な実験費用により,HLA遺伝子配列の詳細な個人差の解明は遅れていました。
本共同研究グループは,最先端のゲノム配列解読技術である次世代シークエンス技術を駆使して,日本人集団1,120名を対象に33のHLA遺伝子におけるゲノム配列を決定することに成功しました。得られたHLA遺伝子ゲノム配列情報に対して機械学習手法を適用した結果,日本人集団の白血球の血液型を11パターンの組み合わせに分類可能なことが明らかになりました。これは,複雑なヒトゲノム情報の解釈を,機械学習手法を用いて実現した先進的な成功例と評価することができます。
さらに,日本人集団17万人のゲノムデータを対象に,白血球の血液型をコンピューター上で高精度に推定することに成功しました。推定された血液型パターンに基づき,病気や量的形質を含む100を超える多彩な表現型(※5)との関連を網羅的に調べるフェノムワイド関連解析(※6)を実施した結果,50以上の表現型において,白血球の血液型が発症に関与していることが明らかになりました。
本研究成果により,日本人集団における白血球の血液型の全容が解明されました。機械学習による白血球の血液型の分類に成功したことは,生命科学研究における機械学習の画期的な応用例と考えられます。さらに,白血球の血液型を用いた個別化医療の実現に貢献するものと期待されます。
本研究成果は,1月29日(英国時間)に英国科学誌「Nature Genetics」のオンライン版に掲載されました。
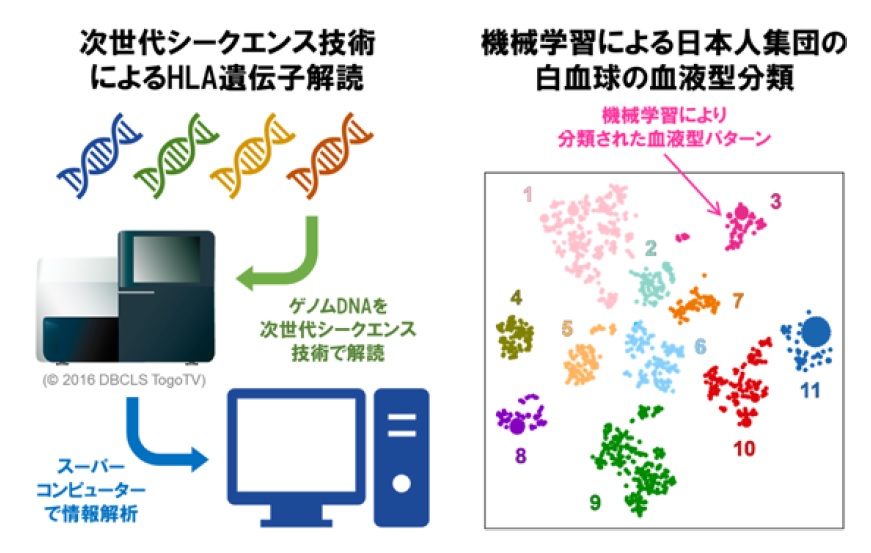
図. 機械学習と次世代シークエンス技術の活用による白血球の血液型解析イメージ((C)大阪大学)
【用語解説】
※1 次世代シークエンス技術
生物のゲノムを構成するDNA配列を高速に解読する技術。従来のゲノム解読手法であるサンガー法と比較して桁違いのスループットを誇り,幅広い生命科学研究における重要なツールとなっている。
※2 機械学習
コンピューターに高次元データを学習させることで,データの内部に潜む特徴的なパターンを見つけ出すデータ解析手法の総称。
※3 HLA遺伝子
ヒトの血球細胞の一種である白血球の表面に発現する分子で,白血球の血液型を規定する。生体内における自己と非自己の認識や外来性の病原菌に対する免疫反応を司り,多彩な表現型の個人差を規定している。主要な古典的HLA遺伝子においては生物学的な役割の研究や検査方法の開発が進んでいるが,その他の非古典的HLA遺伝子については解明が遅れている。
※4 個別化医療
画一的な標準医療でなく,ヒトゲノム情報の違いなど患者一人一人の個性を考慮して施す次世代の医療。
※5 表現型
生物の外見や特徴として表現された形態的・生理的性質。代表的なヒトの表現型として,病気や身体的特徴(身長・肥満),血液検査結果,生理検査結果などが含まれる。
※6 フェノムワイド関連解析
特定の遺伝子変異に着目し,多数の表現型との関連を網羅的に検討する解析手法。
・ 詳しくはこちら
・ 研究者情報:細道 一善